Imaginaire
Imaginaire is a pytorch library that contains
optimized implementation of several image and video synthesis methods developed at NVIDIA.
License
Imaginaire is released under NVIDIA Software license.
For commercial use, please consult researchinquiries@nvidia.com
What's inside?
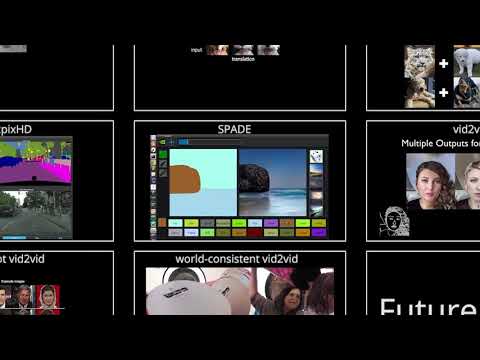
We have a tutorial for each model. Click on the model name, and your browser should take you to the tutorial page for the project.
Supervised Image-to-Image Translation, Algorithm Name, Feature, Publication, :--------------------------------------------, :----------------------------------------------------------------------------------------------------------------, --------------------------------------------------------------:, pix2pixHD, Learn a mapping that converts a semantic image to a high-resolution photorealistic image., Wang et. al. CVPR 2018, SPADE, Improve pix2pixHD on handling diverse input labels and delivering better output quality., Park et. al. CVPR 2019, ### Unsupervised Image-to-Image Translation, Algorithm Name, Feature, Publication, :--------------------------------------------, :----------------------------------------------------------------------------------------------------------------, --------------------------------------------------------------:, UNIT, Learn a one-to-one mapping between two visual domains., Liu et. al. NeurIPS 2017, MUNIT, Learn a many-to-many mapping between two visual domains., Huang et. al. ECCV 2018, FUNIT, Learn a style-guided image translation model that can generate translations in unseen domains., Liu et. al. ICCV 2019, COCO-FUNIT, Improve FUNIT with a content-conditioned style encoding scheme for style code computation., Saito et. al. ECCV 2020, ### Video-to-video Translation, Algorithm Name, Feature, Publication, :--------------------------------------------, :----------------------------------------------------------------------------------------------------------------, --------------------------------------------------------------:, vid2vid, Learn a mapping that converts a semantic video to a photorealistic video., Wang et. al. NeurIPS 2018, fs-vid2vid, Learn a subject-agnostic mapping that converts a semantic video and an example image to a photoreslitic video., Wang et. al. NeurIPS 2019, wc-vid2vid, Improve vid2vid on view consistency and long-term consistency., Mallya et. al. ECCV 2020