KataGo(卡塔戈)
简介
截至到 2020 年中期,KataGo 是最强大的开源围棋机器人之一,在大多数位置上应该比 Leela Zero 更强大。
KataGo 是使用类似 AlphaZero 的过程进行训练的,并进行了许多修改和增强,从而极大地改善了自学学习,完全从零开始学习,没有外部数据。它的某些增强功能利用了游戏特有的特性和训练目标,但也有许多技术是通用的,可以应用到其他游戏中。因此,早期训练是远远快于其他零度风格机器人 -- 仅用了几天几个强大的 GPU,任何研究人员/爱好者都应该能够在完整的 19x19 棋盘上训练从无到高的神经网络。如果调整得当,则仅使用单个高端消费者 GPU 进行的训练就可能在几个月内将机器人从零开始训练为超越人类的专业水平。
在实验上,KataGo 还在2020年6月运行结束时尝试了使用外部数据的一些有限方法。结果好坏参半,似乎没有明显改善整体游戏强度,在此之前,该水平已经超过了其他已知开源机器人的水平。
KataGo 的最新运行使用了约 28个 GPU,而不是数千个(如 AlphaZero 和 ELF),在大约三到六天内就首次在该硬件上达到了超人的水平,并在约 14天 之内达到了与 ELF 类似的强度。经过较小的调整和更多的 GPU,从 40天左右开始,它在具有不同配置、时间控制和硬件的一些测试中大致超过了 Leela Zero。运行持续了大约五个月的训练时间,比 Leela Zero 和其他可能的开源机器人强了数百个 Elo。比赛目前已经结束,但我们希望能够继续进行下去,或者将来再开始!
关于 KataGo 中使用的主要新思想和技术的论文:加速围棋自学(arXiv)。在最近的运行中还发现了一些本文没有描述的进一步的改进 -- 一些关于这方面的文章可能最终会出现。
非常感谢 Jane Street 提供了训练 KataGo 所需的计算能力,以及运行许多较小的测试运行和实验所必需的计算能力。关于最初版本和一些有趣的后续实验的博客文章:
KataGo 的引擎也致力于成为围棋玩家和开发者的有用工具,并支持以下特性:
- 除了能在超人类水平上真正影响比赛结果的步法外,还能帮助分析段位和业余段游戏(kyu and amateur dan games)的疆域和得分,而不仅仅是胜率。
- 关心最大化的分数,在落后的比赛中发挥出色的打法以及在获胜时减少残局中的打法。
- 支持可选的 komi 值(包括整数值)和良好的多让分比赛发挥。
- 支持的棋盘尺寸从 7x7 到 19x19 不等,截至2020年5月,它可能是9x9和13x13上最强大的开源机器人。
- 支持各种各样的规则,包括在几乎所有常见情况下匹配日本规则的规则,以及类似古代数石规则的规则。
- 对于工具/后端开发人员 -- 支持一个基于 JSON 的分析引擎,它可以高效地对多个游戏进行批处理,并且比 GTP 更容易使用。
现状和历史
KataGo 已完成第三次主要正式比赛!它持续了大约5个月的时间(从2019年12月到2020年6月)(在这段时间内,KataGo 并没有完全连续运行),并且似乎已经超过了 Leela Zero 最终的官方40块网,而且出场次数适中(数千到低)数以万计),包括只有20个区块的网络。早些时候,它仅在大约 12-14天 就超过了从2019年6月开始的之前的19天官方运行,到最后达到了700多Elo。这是由于先前的训练中没有进行各种训练上的改进。除了更快取得更强的成绩外,第三轮还增加了对日本规则,更强的让分盘和更准确的得分估算的支持。
强大的网络可供下载!有关最新版本和这些神经网络,请参见发布页面。在这里可以找到更古老和替代的神经网络的历史,包括一些非常强大的较小的网络。这其中包括一个快速的 10-block 网络,几乎可以与许多早期的 15-block 网络相媲美,其中包括去年的 KataGo 最佳 15-block 网络和 Leela Zero 的 LZ150。这个新的运行过程还具有非常强大的 15-block 网络,该网络应该至少有几千场淘汰赛,相当于 20-block 网络 ELFv2 的强度。它们对于硬件较弱的用户可能有用。然而,KataGo 最新的 20-block 网络比 15-block 网络要强大得多(在相同的情况下,可能是 500-800 Elo!),即使在相当弱的硬件上,即使考虑到它运行的速度有多慢,它也可能主导 15-block 网络。
这是在 157 个训练日的过程中改善的图表:
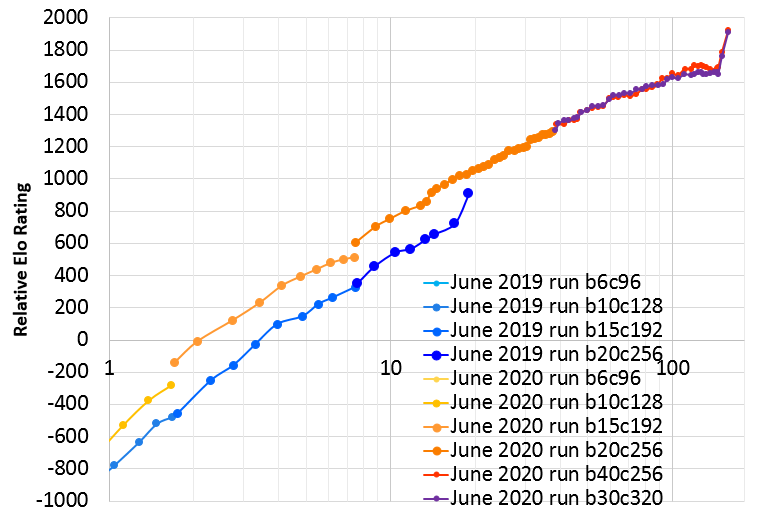
|
| X 轴是训练天数,对数刻度。 (注意:在此期间,硬件并不完全一致,但大多数时候是 44 个 V100 GPU)。Y 轴是基于 1200 次访问测试匹配的相对 Elo 等级。每次运行结束时的突然跳跃是由于这些运行结束时的学习速度下降所致。 2020 年 6 月跳高之前的不稳定,尤其是在 40 块的 Elo 中尤为明显,这是由于该运行的最后 40 天被用来进行实验性更改,并非所有更改都是改进。117 天是这些更改之前的最后“清洁”点。 |
运行的前 117 天干净整洁,并遵循“半零”标准。特别是,使用了特定于游戏的输入功能和辅助训练目标,其中大部分在 KataGo 的论文中进行了描述。但是,除了一些小的优化以更快地结束完成的游戏之外,没有使用外部数据,也没有使用任何特殊的试探法或专家逻辑来编码偏向或选择动作的搜索。通过高级超参数(例如降低学习率,扩大神经网络的时间表等),仅对正在进行的培训进行最小的调整。然后,运行的最后40天开始尝试使用外部数据查看效果的一些有限方式。
整个运行过程中,大部分时间使用了约 46 个GPU。其中有 40 个用于自玩数据生成,多达 4 个用于训练跑步的主要神经网络,还有 2 个用于门控游戏。在前 14 天中,仅使用 28 个GPU 超过了去年的运行速度。在第 14 天到第 38 天,它增加到了 36 个GPU,然后从第38天起又增加到当前的 46 个GPU,这是其余运行所使用的数量。在过去 40 天的实验更改中,有时还会使用一个额外的第 47 个GPU。此外,有时最多使用 3 个GPU来训练一些额外的网络,例如为硬件较弱的最终用户扩展较小的网络,但是这些在正常运行中没有任何作用。
只是为了好玩,是所选版本 Elo 强度的表,这些表基于一个池(1200 人次)中的这些版本与其他版本之间的数以万计的游戏。这些基于固定的搜索树大小,而不是固定的计算时间。最初的 117 天:
| Neural Net(神经网络) | Note | Approx Days Selfplay | Elo |
|---|---|---|---|
| g170-b6c96-s175395328-d26788732 | (last selfplay 6 block) | 0.75 | -1184 |
| g170-b10c128-s197428736-d67404019 | (last selfplay 10 block) | 1.75 | -280 |
| g170e-b10c128-s1141046784-d204142634 | (extended training 10 block) | - | 300 |
| g170-b15c192-s497233664-d149638345 | (last selfplay 15 block) | 7.5 | 512 |
| g170e-b15c192-s1305382144-d335919935 | (extended training 15 block) | - | 876 |
| g170e-b15c192-s1672170752-d466197061 | (extended training 15 block) | - | 935 |
| g170-b20c256x2-s668214784-d222255714 | (20 block) | 15.5 | 959 |
| g170-b20c256x2-s1039565568-d285739972 | (20 block) | 21.5 | 1073 |
| g170-b20c256x2-s1420141824-d350969033 | (20 block) | 27.5 | 1176 |
| g170-b20c256x2-s1913382912-d435450331 | (20 block) | 35.5 | 1269 |
| g170-b20c256x2-s2107843328-d468617949 | (last selfplay 20 block) | 38.5 | 1293 |
| g170e-b20c256x2-s2430231552-d525879064 | (extended training 20 block) | 47.5 | 1346 |
| g170-b30c320x2-s1287828224-d525929064 | (30 block more channels) | 47.5 | 1412 |
| g170-b40c256x2-s1349368064-d524332537 | (40 block less channels) | 47 | 1406 |
| g170e-b20c256x2-s2971705856-d633407024 | (extended training 20 block) | 64.5 | 1413 |
| g170-b30c320x2-s1840604672-d633482024 | (30 block more channels) | 64.5 | 1524 |
| g170-b40c256x2-s1929311744-d633132024 | (40 block less channels) | 64.5 | 1510 |
| g170e-b20c256x2-s3354994176-d716845198 | (extended training 20 block) | 78 | 1455 |
| g170-b30c320x2-s2271129088-d716970897 | (30 block more channels) | 78 | 1551 |
| g170-b40c256x2-s2383550464-d716628997 | (40 block less channels) | 78 | 1554 |
| g170e-b20c256x2-s3761649408-d809581368 | (extended training 20 block) | 92 | 1513 |
| g170-b30c320x2-s2846858752-d829865719 | (30 block more channels) | 96 | 1619 |
| g170-b40c256x2-s2990766336-d830712531 | (40 block less channels) | 96 | 1613 |
| g170e-b20c256x2-s4384473088-d968438914 | (extended training 20 block) | 117 | 1529 |
| g170-b30c320x2-s3530176512-d968463914 | (30 block more channels) | 117 | 1643 |
| g170-b40c256x2-s3708042240-d967973220 | (40 block less channels) | 117 | 1687 |
神经网络在过去的 40 天里进行了一些更实验性的训练改变,尝试了包括外部数据在内的各种训练改变,结果喜忧参半:
| Neural Net | Note | Approx Days Selfplay | Elo |
|---|---|---|---|
| g170-b30c320x2-s3910534144-d1045712926 | (30 block more channels) | 129 | 1651 |
| g170-b40c256x2-s4120339456-d1045882697 | (40 block less channels) | 129 | 1698 |
| g170e-b20c256x2-s4667204096-d1045479207 | (extended training 20 block) | 129 | 1561 |
| g170-b30c320x2-s4141693952-d1091071549 | (30 block more channels) | 136.5 | 1653 |
| g170-b40c256x2-s4368856832-d1091190099 | (40 block less channels) | 136.5 | 1680 |
| g170e-b20c256x2-s4842585088-d1091433838 | (extended training 20 block) | 136.5 | 1547 |
| g170-b30c320x2-s4432082944-d1149895217 | (30 block more channels) | 145.5 | 1648 |
| g170-b40c256x2-s4679779328-d1149909226 | (40 block less channels) | 145.5 | 1690 |
| g170e-b20c256x2-s5055114240-d1149032340 | (extended training 20 block) | 145.5 | 1539 |
最终产生的神经网络学习速率下降。这里继续了一些对外部数据的实验使用,但是最大的收获肯定是由于学习速率下降而不是这些使用。该表中的最后三个网是 KataGo 这次运行的最终网!
| Neural Net | Note | Approx Days Selfplay | Elo |
|---|---|---|---|
| g170-b30c320x2-s4574191104-d1178681586 | (learning rate drop by 3.5x) | 150 | 1759 |
| g170-b40c256x2-s4833666560-d1179059206 | (learning rate drop by 3.5x) | 150 | 1788 |
| g170e-b20c256x2-s5132547840-d1177695086 | (learning rate drop by 2x) | 150 | 1577 |
| g170-b30c320x2-s4824661760-d122953669 | (learning rate drop by another 2x) | 157 | 1908 |
| g170-b40c256x2-s5095420928-d1229425124 | (learning rate drop by another 2x) | 157 | 1919 |
| g170e-b20c256x2-s5303129600-d1228401921 | (learning rate drop by another 2x) | 157 | 1645 |
与 2019 年 6 月的官方运行进行比较:(这些 Elos 是直接测量的,而不是推断的,因为这些较老的网络在同一个测试游戏池中直接竞争):
| Neural Net | Note | Approx Days Selfplay | Elo |
|---|---|---|---|
| g104-b6c96-s97778688-d23397744 | (last selfplay 6 block) | 0.75 | -1146 |
| g104-b10c128-s110887936-d54937276 | (last selfplay 10 block) | 1.75 | -476 |
| g104-b15c192-s297383936-d140330251 | (last selfplay 15 block) | 7.5 | 327 |
| g104-b20c256-s447913472-d241840887 | (last selfplay 20 block) | 19 | 908 |
在哪里下载资料
您可以在 Windows 和 Linux 的发布页面上下载 KataGo 的预编译可执行文件。
您可以从发布页面下载一些选定的神经网络,或从此处下载其他其他神经网络。有两种不同的模型格式,分别用 “.txt.gz” 和 “.bin.gz” 表示。这是由于从v1.3.3开始,模型格式发生了变化 -- KataGo的最新版本同时支持这两种格式,但是后者在磁盘上更小,加载速度更快。
设置并运行 KataGo
KataGo 仅实现了一个 GTP 引擎,这是围棋软件使用的简单文本协议。它本身没有图形界面。因此,一般来说,您将希望将 KataGo 与 GUI 或分析程序一起使用。其中一些捆绑了 KataGo 的下载文件,这样您就可以从一个地方获得所有内容,而不是分别下载并管理文件路径和命令。
图形用户界面
这绝不是一个完整的清单 -- 那里有很多东西。但是,截至2020年,一些更容易和/或更受欢迎的可能是:
- KaTrain -- 对于非技术用户来说,KaTrain 可能是最容易设置的,它提供了一个集所有功能于一体的软件包(不需要单独下载KataGo !)、针对较弱玩家的修改强度机器人以及良好的分析特性
- Lizzie -- Lizzie 非常受欢迎,因为它可以运行长时间的交互式分析,并在分析发生时将其可视化。Lizzie 还提供了一个一站式服务。但是请记住,正如这里所描述的,KataGo 的 OpenCL 版本在第一次启动时可能需要很长时间来调优和加载,Lizzie 在显示这个进展时做得很糟糕。万一出现实际的错误或失败,Lizzie 的界面并不能很好地解释这些错误,而且看起来会永远挂起。Lizzie 打包的 KataGo 版本非常强大,但不一定是最新最强的。因此,一旦你让它工作,你可能要从发布页面下载 KataGo 和一个更新的网络,并用它们替换 Lizzie 的版本。
- q5Go 和 Sabaki 是支持 KataGo 的通用 SGF 编辑器和 GUI,包括 KataGo 的得分估算和许多高质量功能。
通常,对于不提供集所有功能于一体的包的 GUI,您需要下载 KataGo(或您选择的任何其他围棋引擎!),并告诉 GUI 运行适当的命令行以调用您的引擎。并包含正确的文件路径。有关 KataGo 命令行界面的详细信息,请参见下面的“如何使用”。
Windows 和 Linux
KataGo 当前正式支持 Windows 和 Linux,并在每个版本中提供预编译的可执行文件。 并非所有不同的 OS 版本和编译器都已经过测试,因此,如果遇到问题,请随时提出问题。 当然,也可以通过 Windows 上的 MSVC 通过 Windows 上的源代码,或通过 g++ 等常用的编译器从 Linux 上的源代码编译 KataGo,该文档将在后面进行介绍。
MacOS
该社区还在 MacOS 上提供了 Homebrew 的 KataGo 软件包 -- 发行版可能会稍微落后于正式发行版。
使用 brew install katago。 最新的配置文件和网络安装在 KataGo 的 share 目录中。 通过 brew list --verbose katago 找到它们。 运行 katago 的基本方法是:
katago gtp -config $(brew list --verbose katago | grep gtp) -model $(brew list --verbose katago | grep .gz | head -1)
您应该根据此处的发行说明选择网络,并像安装 KataGo 的所有其他方式一样自定义提供的示例配置。
OpenCL 与 CUDA
KataGo 同时具有 OpenCL 版本和 CUDA 版本。
- CUDA 版本需要安装 CUDA 和 CUDNN 以及一个现代的 NVIDIA GPU。
- OpenCL 版本应该能够与许多其他支持 OpenCL 的 GPU 或加速器一起运行,例如 AMD GPU,以及基于 CPU 的 OpenCL 实现或诸如 Intel Integrated Graphics 之类的东西。 (注意:尽管 Intel 集成显卡是一个折腾 -- 英特尔 OpenCL 的许多版本似乎有问题)。它也不需要 CUDA 和 CUDNN 那样的麻烦,而且只要您有一个像样的现代 GPU,就更有可能实现开箱即用。但是,在第一次运行时,它需要花费一些时间来调整自己。对于许多系统,这将需要 5 到 30 秒,但是在一些较旧/较慢的系统上,则可能需要数分钟或更长时间。
大多数用户报告说,OpenCL 版本比 CUDA 版本要快,除非您的 GPU 是支持 FP16 和张量内核的高端 NVIDIA GPU。然后,CUDA版本可能会更快一些,因此会更强大(但将来可能会进一步优化 OpenCL 实现)。
对于这两种实施方式,如果您关心最优性能,建议您也调优所使用的线程数量,因为这可能会在速度上造成 2-3 倍的差异。请参阅下面的“性能调优”。但是,如果您只是想使其正常工作,那么默认的未调整设置也应该是合理的。
如何使用
再次,KataGo 只是一个引擎,没有自己的图形化界面。因此,通常您会希望将 KataGo 与 GUI 或分析程序一起使用。如果在设置过程中遇到任何问题,请查看常见问题和问题。
KataGo 支持多个命令。
所有这些命令都需要一个包含神经网络的“model”文件,该文件以 .bin.gz 或 .txt.gz 结尾,有时也只是 .gz 扩展名。但是,如果模型名为 default_model.bin.gz 或 default_model.txt.gz,并且位于与 katago 可执行文件相同的目录中,则可以省略指定模型的步骤。
其中大多数命令还需要一个以 .cfg 结尾的 GTP“config”文件,该文件指定有关 KataGo 行为方式的参数。但是,如果 GTP 配置名为 default_gtp.cfg,并且与 katago 可执行文件位于同一目录中,则可以忽略指定。
如果您是第一次运行 KataGo,则可能需要先在命令行上运行基准测试或 genconfig 命令,以测试 KataGo 是否正常工作并选择多个线程。在 OpenCL 版本上,给 KataGo 一个自动调整 OpenCL 的机会,这可能需要一段时间。
要使用下载的 KataGo 神经网络和 GTP 配置运行 GTP 引擎,请执行以下操作:
./katago gtp -model <NEURALNET>.gz -config <GTP_CONFIG>.cfg- 或者从不同的途径:
whatever/path/to/katago gtp -model whatever/path/to/<NEURALNET>.gz -config /whatever/path/to/<GTP_CONFIG>.cfg - 这是用来告诉你的 GUI (Lizzie, q5Go, Sabaki, GoGui, 等)来运行 KataGo 的命令 (当然,所有的实际路径都被替换了)。
或如前所述,如果您在与 KataGo 相同的目录中具有正确命名的默认配置和模型:
./katago gtp- 或者从不同的途径:
whatever/path/to/katago gtp - 另外,这是您要告诉您的(Lizzie, q5Go, Sabaki, GoGui, 等)来运行 KataGo 的命令 (如果您具有默认配置和模型)。
运行基准测试以测试性能并帮助您选择要使用多少线程以获得最佳性能。 然后,您可以手动编辑GTP配置以使用以下多个线程:
./katago benchmark -model <NEURALNET>.gz -config <GTP_CONFIG>.cfg
或如前所述,如果您在与KataGo相同的目录中具有正确命名的默认配置和模型:
./katago benchmark
要根据提出的简单问题为您自动调整线程和其他设置,并为您生成 GTP 配置:
./katago genconfig -model <NEURALNET>.gz -output <PATH_TO_SAVE_GTP_CONFIG>.cfg
运行基于 JSON 的分析引擎,该引擎可以对后端 Go 服务进行高效的批处理评估:
./katago analysis -model <NEURALNET>.gz -config <ANALYSIS_CONFIG>.cfg -analysis-threads N
调整性能
优化 KataGo 性能的最重要参数是要使用的线程数-这很容易造成 2 或 3 倍的差异。
其次,您还可以读取 GTP 配置中的参数(default_gtp.cfg 或 gtp_example.cfg 或 configs/gtp_example.cfg 等)。此处介绍了许多其他设置,您可以设置这些设置来调整 KataGo 的资源使用情况,或选择要使用的 GPU。您还可以调整诸如 KataGo 的认输阈值、思考行为或实用程序功能之类的内容。大多数参数直接内联在示例配置文件中。 通过上述 genconfig 命令生成配置时,也可以交互设置许多选项。
常见问题
本节总结了运行 KataGo 时的一些常见问题。(恕删略,请参考自述文件)
编译 KataGo
KataGo 是用 C++ 写的。它应该通过至少支持 C++ 14 的 g++ 在 Linux 或 OSX 上编译,或者通过 MSVC 15(2017) 或更高版本在 Windows 上进行编译。其他编译器和系统还没有经过测试。如果您想自己运行完整的 KataGo 自玩训练循环,或者进行自己的研究和实验,或者您想在没有预编译可执行文件可用的操作系统上运行 KataGo,那么建议您这样做。
自学训练:
如果你还想运行完整的自玩循环,并使用这里的代码训练你自己的神经网络,请参阅自玩训练。
贡献者
非常感谢为这个项目做出贡献的各种人! 请参阅贡献者以获取贡献者列表。
许可
除了此仓库文件中 cpp/external/ 下包含的几个外部库以及单个文件 cpp/core/sha2.cpp 均具有自己的单独许可证之外,此仓库文件中的所有代码和其他内容均已发布。 可在以下文件的许可下免费使用或修改:LICENSE。
除了许可证,如果您最终使用此存储库中的任何代码来进行自己的任何酷炫的新自玩游戏或神经网络训练实验,我(lightvector)都希望听到它。
(The first version translated by vz on 2020.07.18)